.png)

如何让龙虾过目不忘:OpenClaw 记忆配置完全指南
前言:你是否也遇到过这种情况?

昨天你花了半小时跟龙虾讲清楚你的项目背景、偏好设定、关键约束。它当时反应很快,给出的建议也很贴合。
今天再问它类似的问题,它像第一次见你。
你开始怀疑:这玩意儿是不是根本记不住?
更糟糕的是,有时候它会牢牢记住无关紧要的闲聊,却把真正重要的偏好、项目背景、配置细节忘得干干净净。
这不是你一个人的问题。
很多 OpenClaw 用户都会遇到:昨天还聊得好好的,今天就不认识我了。你以为自己在和一个越来越懂你的 AI 协作,实际上每次都在反复给它做 onboarding。
先别急着怪龙虾"失忆"。
这篇文章要告诉你:很多时候,龙虾"记不住",不是因为它不会记,而是因为它的"检索系统"根本没完全跑起来。
就像你把文件存进了硬盘,但搜索功能坏了——文件明明在那里,就是找不到。
好消息是:这个问题解决起来比你想象的简单得多。
第一部分:OpenClaw 自带记忆,为什么会让人误以为它失忆
记忆不是黑箱,而是 Markdown 文件
OpenClaw 的记忆,真实来源不是某个神秘数据库,而是你 agent workspace 里的 Markdown 文件:
memory/YYYY-MM-DD.md:每日记忆,追加写入MEMORY.md:长期记忆,存放稳定偏好、长期事实、重要决定
这意味着一个很关键的判断:
OpenClaw 不是"有没有记忆"的问题,而是"哪些内容被写进文件、哪些内容被检索出来"的问题。
默认是双层记忆
官方说明的默认层次:
- 会话启动时读取 今天 + 昨天 的 daily memory
- 再读取可选的
MEMORY.md MEMORY.md只在主私有会话加载,不在 group contexts 中加载
所以很多人觉得"龙虾昨天还记得,今天就失忆了",其实背后不是完全失忆,而是:
- 最近两天的内容更容易直接进入上下文
- 更早的内容需要靠 memory_search 检索命中
- 没写入
MEMORY.md的重要信息,可能只是埋在 daily log 里,不一定每次都能被及时召回
两个核心记忆工具
官方文档明确提到:
memory_search:对索引片段做语义召回memory_get:精确读取某个 Markdown 文件 / 行范围
这里可以形成一个直觉比喻:
memory_get像"按文件翻档案"memory_search像"先搜关键词和语义,再把相关档案片段捞出来"
真正决定"像不像记住"的,通常不是 get,而是 search 的质量。
向量检索不是默认无脑可用(这是重点)
OpenClaw 支持向量检索,但有一个高频坑:
- memory search 默认启用
- 但向量能力依赖 embedding provider
- 如果
agents.defaults.memorySearch.provider没配置好,或者 embedding API key 没有单独补齐,语义检索能力就会失效
这就是全文最关键的误区:
不是记忆没写,而是 semantic recall 没跑起来。
很多人以为"默认就全都生效了",结果:
- 搜索效率低,只能靠字面关键词撞运气
- 记忆效力低,明明写进 daily memory 或 MEMORY 了,但语义相近的内容就是捞不出来
你以为是记忆能力不行,很多时候其实只是检索系统还停留在"半开状态"。
先把向量模型配起来

OpenClaw 原生记忆的最小配置示例(引用自配置参考文档):
{
"agents": {
"defaults": {
"memorySearch": {
"provider": "openai",
"remote": {
"baseUrl": "https://api.siliconflow.cn/v1",
"apiKey": "your-api-key",
"batch": {
"enabled": false -- 是否批量索引
}
},
"fallback": "none",
"model": "BAAI/bge-m3"
}
}
}
}
推荐模型:硅基流动 BAAI/bge-m3
- 完全免费,无门槛
- 普通用户完全够用
- 中文支持优秀
- 性能稳定
注册地址:https://cloud.siliconflow.cn/i/Huhl1bDo
配置后必须执行的命令:
# 重启网关(配置后必须)
openclaw gateway restart
# 重建记忆索引
openclaw memory index --force
# 查看记忆索引状态(深度)
openclaw memory status --deep
# 搜索记忆验证
openclaw memory search "测试关键词"
Hybrid Search 的真正价值
OpenClaw 支持:
- BM25 负责字面命中
- Vector 负责语义相近
- RRF 负责融合结果
- MMR 负责去重和多样性
- Temporal Decay 让近期记忆更容易被捞出来
大白话解释要点:
它不是多加几个名词,而是让"你换个说法,它也大概率还能想起来"。
怎么验证真的生效
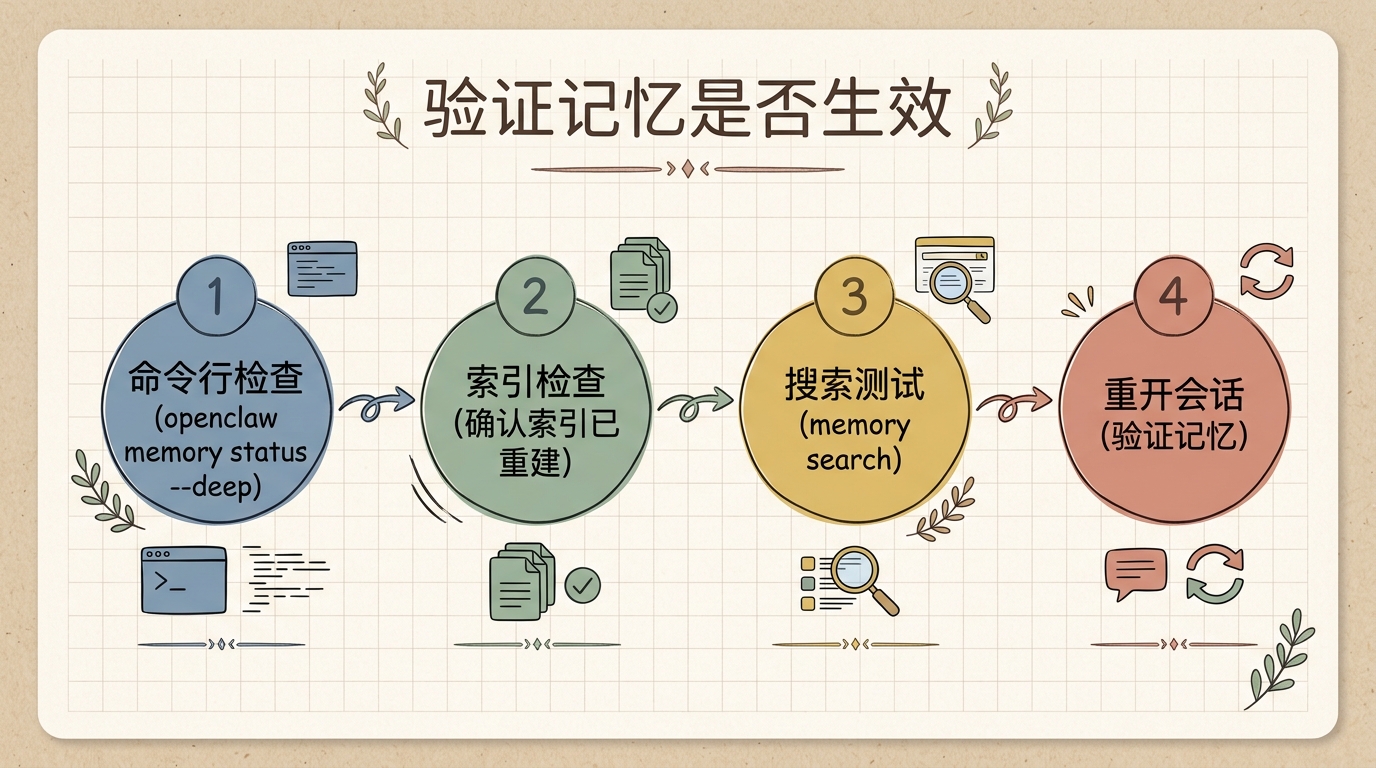
不是只看配置文件写没写,而是要做验证闭环:
- 命令行检查:
openclaw memory status --deep - 索引检查:确认索引已经重建
- 搜索测试:
openclaw memory search "你之前告诉过我的重要信息" - 重开会话复测:第一轮告诉它一个重要信息,第二轮重新开启会话,问"你记得我之前说的xxx吗?"
第二部分:MemOS 为什么更像给龙虾加了一层长期大脑
先把定位说透:
MemOS 不是简单外挂,也不是"再加一个向量库"。
它更像把记忆这件事,从"有文件可查"升级成"有流程、有分层、有演化"。
四条核心流水线
MemOS 给 OpenClaw 增加的不是一个普通外挂,而是一整层长期记忆基础设施:
- 记忆写入:自动捕获 → 分块 → 摘要 → 向量化 → 去重 → 存储
- 任务总结:把碎片对话整理成任务单元
- 技能进化:把做完的任务继续抽成可复用 skill
- 智能检索:FTS5 + Vector + RRF + MMR + 时间衰减 + LLM filter
这意味着 MemOS 在讲的已经不是"记住一段话",而是:
从对话碎片 → 任务经验 → 可复用技能 的完整演化链路。
Task → Skill 的升级逻辑
MemOS 首页和文档都反复强调:
- 对话会先被聚合成 task
- 再判断是否值得生成 skill
- skill 会继续被 refine / extend / fix
- 最终形成版本化能力沉淀
这就是它和原生 memory 最大的区别:
- 原生 memory 更像"记事本 + 检索器"
- MemOS 更像"记忆系统 + 经验沉淀器 + 技能复用器"
多 Agent 记忆隔离与共享
MemOS 文档明确强调:
- 每个 Agent 有自己的私域记忆
- 私域之间互不可见
- 但可以通过 public memory / skill sharing 共享公共知识和技能
这是一个非常适合第二维去展开的点:
- OpenClaw 原生 memory 更偏"单 Agent 文件记忆"
- MemOS 更适合"多 Agent 协作系统"
真正的问题不是"一个龙虾记不记得",而是"一群龙虾能不能各记各的,同时又共享真正该共享的经验"。
本地化、可视化、分级模型
MemOS Local 的核心卖点很明确:
- 记忆、任务、技能都存本机 SQLite
- Viewer 仅运行在
127.0.0.1 - 支持密码保护
- 零云依赖
本地版有可视化面板,能直接看记忆、任务、技能。不同环节可以拆给不同模型,成本更可控。
MemOS 云端版最小接入命令:
# 环境变量配置
export MEMOS_API_KEY="your-memos-api-key"
# 安装云插件
npm install -g @memos-claw/memos-cloud-openclaw-plugin
MemOS 本地版安装命令和本地面板地址:
# 安装本地插件
npm install -g @memos-claw/memos-local-openclaw-plugin
# Web 管理面板
http://127.0.0.1:18799
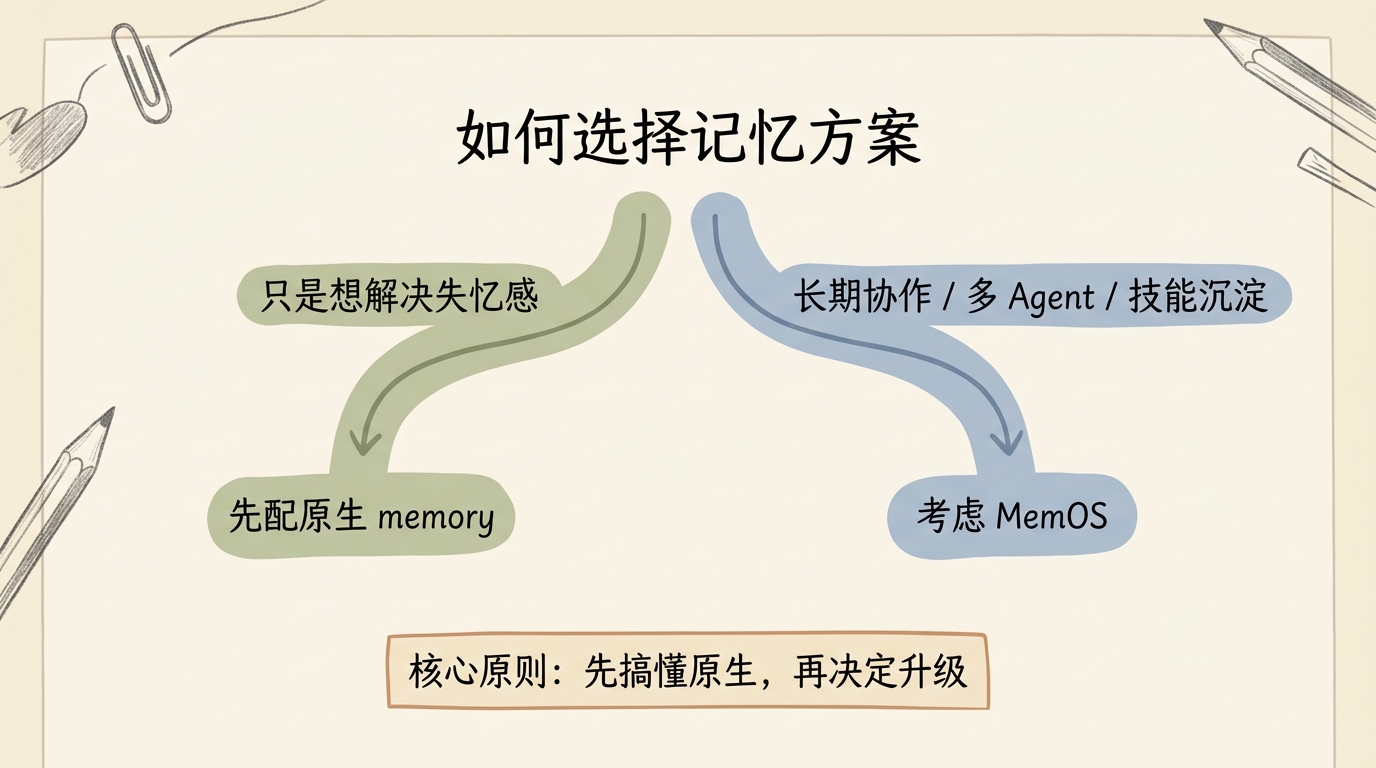
第三部分:什么时候该上 MemOS
先把原生 memory 配对
给出一条稳妥上手路线:
- 检查
~/.openclaw/openclaw.json里有没有agents.defaults.memorySearch - 先把免费 embedding 配上,优先推荐硅基流动
BAAI/bge-m3 - 重启 gateway,重建 memory index
- 用
memory status --deep和memory search做验证 - 原生 memory 跑通以后,再决定要不要加 MemOS
判断清单
可以整理成一个判断清单:
- 只是想让龙虾别再像失忆:先搞原生 memory
- 已经开始积累长期工作流:考虑 MemOS
- 已经需要任务复盘和技能沉淀:MemOS 优先级明显提高
第三人称视角的落点:
新手用户最该先解决的是"原生 memory 能不能稳定工作"。
已经有长期任务流、多 Agent 分工、技能沉淀需求的团队,再去接 MemOS 更划算。
总结:如何让龙虾真正过目不忘
这篇文章讲了一件事:
你以为是龙虾"失忆",很多时候只是向量模型没配好。
记住这三句话
- 先搞懂原生 memory:OpenClaw 自带的记忆系统足够解决大部分"失忆"问题
- 把向量模型配起来:硅基流动的 BAAI/bge-m3 完全免费,普通用户完全够用
- 再决定要不要加 MemOS:如果你已经有多 Agent 协作、技能沉淀需求,那时再上 MemOS
快速上手路线
# 1. 配置向量模型(免费)
# 注册:https://cloud.siliconflow.cn/i/Huhl1bDo
# 模型:BAAI/bge-m3
# 2. 重启网关
openclaw gateway restart
# 3. 重建索引
openclaw memory index --force
# 4. 验证生效
openclaw memory search "你之前告诉过我的重要信息"
一句话总结
先把原生 memory 配对、验证通,再决定要不要给龙虾加 MemOS。
你的龙虾现在更像是"没写进去",还是"写进去了但捞不出来"?
在评论区告诉我,下一篇我可以针对性地讲讲完整排障流程。
参与讨论
(Participate in the discussion)
参与讨论